Some while back I had a paper published int he Radiation Protection in Australia journal, the official journal of the Australasian Radiation Protection Society. It was a passion project as at the time no-one could tell me why the pass/fail values for the chi-squared test we did for alpha counting were what they were (ref DMP NORM-3.4).
So I deep dived it, wrote up the manuscript, got my wife to help and eventually proof read and BAM – we co-authored a paper together.
This was actually the first time I realised I could contribute back this way and started a landslide of presnetations, a whole website just so I can drop math-bombs (this website) and other ‘things’.
Catching the Risk: The Maths Behind Sample Quotas in SEGs
In occupational hygiene, we often talk about Similar Exposure Groups (SEGs) and the need to collect enough samples to be confident in our data. But how do we actually determine if our sample size is sufficient to capture those at the highest risk?
Standard practice is to mornally just quote Technical Appendix A in NIOSH 173/77 and go from there – but this time, that just wasn’t going to be enough.
During a recent mentoring session, we broke down the statistics of sampling quotas. Here is how the maths of permutations and combinations helps us ensure no worker is left behind.
The Foundation: Factorials and Choices
Before we can calculate the probability of a successful sampling campaign, we need to understand how many ways we can “choose” workers from a group.
Factorials
The factorial ($n!$) is the product of all positive integers less than or equal to $n$. This value represents the total number of ways you can uniquely arrange a set of items. For example, if you have 6 items and want to know every possible sequence they could be ordered in:
Understanding the difference between these two is critical for sampling.
Permutations
How many ways can I choose $r$ things from $n$ things where order is important? To use our example of 6 items, let’s say I want to select 2. I can do that by:
$$6 \times 5 = 30$$
To get that, using only factorials, we can use some numerator/denominator cancellation. It looks like this, noting how $4 \times 3 \times 2 \times 1$ appears in both the top and bottom and so cancel out:
How many ways can I choose $r$ things from $n$ things where order is NOT important? In our example of 30 permutations of 2 items, we divide by the 2 ways those items can be arranged ($2 \times 1 = 2$). So let’s divide our permutation formula by the factorial of $r$:
In a typical hygiene survey, we don’t care about the sequence—only the final set of people monitored. We divide the permutations by the ways those 3 people can be rearranged ($3!$):
Why this matters: There are far fewer unique “groups” than “orders.” We use combinations because we are looking for the probability of a specific subset of the population being captured but what order we select them is not important.
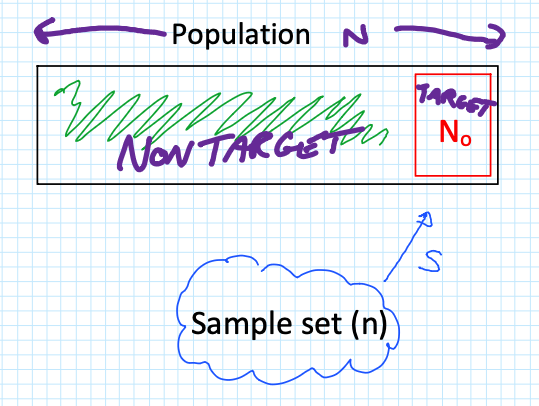
Defining the Sampling Problem
When sampling a population ($N$), we are often looking for a specific “Target” group ($N_0$), such as a Highly Exposed Risk Group (e.g., the top 10% of exposed workers).
The critical question is: What is the probability that I get ZERO samples from my high-risk group?
To find this, we look at the three components of the probability calculation:
Combinations of $n$ samples from the non-target group $(N – N_0)$.
Combinations of 0 samples from the target group $(N_0)$.
Total possible combinations of $n$ samples from the entire population ($N$).
The maths behind this derivation follows a logical flow:
Since any combination of 0 items ($^{N_0}\mathcal{C}_0$) is equal to 1 (there is only 1 way to select nothing; it makes maths-sense, go with it), we expand the factorials as follows:
By simplifying the expressions (flipping the $^N\mathcal{C}_n$ with a $-1$ power) and cancelling out terms (specifically $n!$), we arrive at the final simplified formula:
Let’s apply this to a group of 18 workers ($N=18$). We want to ensure we haven’t missed the top 10% of exposed workers ($18 \times 0.1 = 1.8$, which we call 2 workers, so $N_0 = 2$).
If we collect different sample sizes ($n$), how does your risk of “missing” ($r=0$) that high-risk group change?
Scenario A: Collect 9 Samples ($n=9$)
Using our formula $\frac{(N-N_0)!}{(N-N_0-n)!} \times \frac{(N-n)!}{N!}$:
At 15 samples, the probability of missing the target group is less than 2%, providing a very high level of certainty.
The “Flip It” Rule
In hygiene, we usually want to know the confidence level—the probability of getting at least one sample from the target group ($r \ge 1$). To find this, simply “flip” the result:
$$\text{Confidence} = 1 – P(r=0)$$
With 12 samples, you have a 90.2% confidence level
i.e. $(1-0.098) \times 100$.
With 15 samples, you have a 98.04% confidence level
i.e. $(1-0.0196) \times 100$.
By using these calculations, you can move away from “guessing” your sample quotas and start providing a statistical justification for your monitoring programs.
Like flat-earthers, standard statistical models can sometimes be a little detached from reality. If you work in occupational hygiene, you’re likely intimately familiar with the Normaland Lognormaldistributions. They are the bread and butter of our industry, but they have a specific quirk that drives me nuts: they allow for “infinite tails.”
Mathematically, this means that standard models suggest there is always a tiny, non-zero probability that an exposure result will reach infinity. Obviously, that’s impossible. You can’t have a concentration of a chemical higher than pure vapour, and you can’t fit more dust into a room than the volume of the room itself. This is where the Beta Distribution steps in to save the day, and it’s why I’ve become such a vocal proponent of its use in our field (#AIOHStatsGang).
The strength of the Beta distribution is that it has hard limits. It allows you to define a minimum and a maximum. By setting a ceiling—an upper bound—we stop the model from predicting unrealistically high results. We are effectively telling the math, “Look, physically, the exposure cannot go higher than X.” This seemingly small change completely removes those phantom probabilities of impossible exposure levels, giving us a statistical picture that actually obeys the laws of physics.
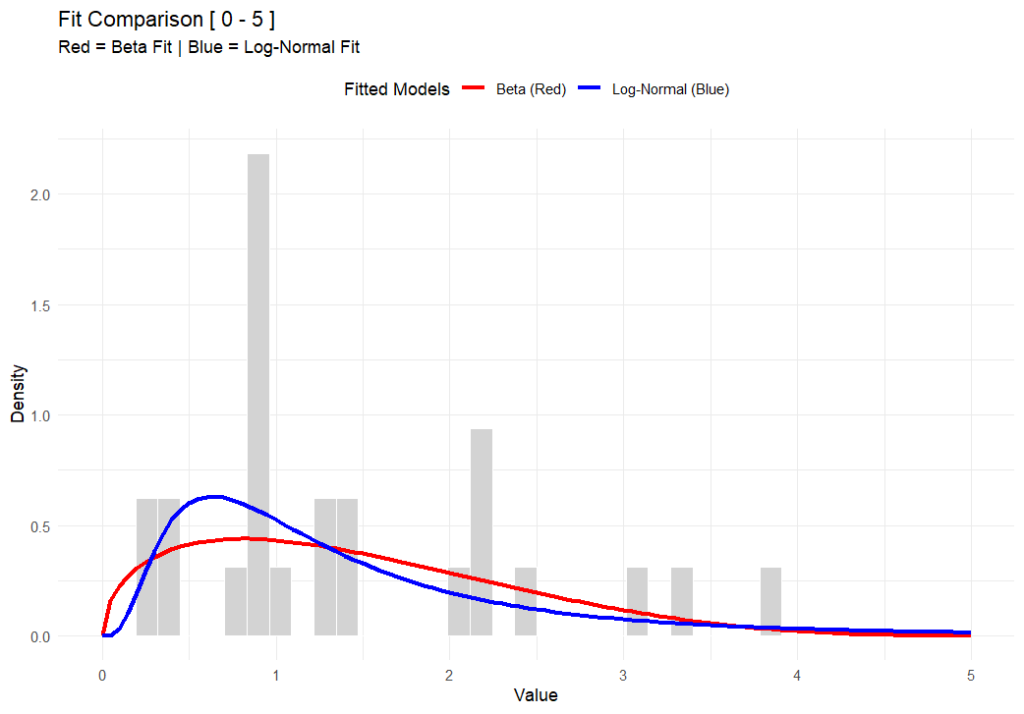
In the chart above (generated using R-base), you can see that while both functions fit the data well, the Beta distribution respects a hard ceiling at 5, whereas the Lognormal tail simply drifts off into the impossible.
But here’s the rub—switching to Beta isn’t for the faint of heart. The Lognormal distribution is easy; you can do it on a napkin with a $5 calculator. The Beta distribution is mathematically more complex and abstract. It’s harder to explain to a layman, and the formulas are heftier. But in my opinion, I’d rather struggle with the math for 10 minutes than present a risk assessment that implies a worker could be exposed to a billion ppm.
This approach also forces us to be better specialists because it brings expert judgement back into the driver’s seat – or at least backseat driving. Because the model relies on fixed boundaries, you can’t just feed it data and walk away. You have to decide where to put those lower and upper bounds based on the specific environment. Today, there are PLENTY of AI tools to help you do this, even in Excel. It forces a deeper engagement with the process conditions rather than blind reliance on a pre-cooked spreadsheet (looking at you IHStat). It might be a headache to set up initially, but a model that respects physical reality is a model worth using.
Further Reading
For a deeper dive into the mathematics of the Beta distribution, check out: